Декодирование JPEG для чайников / Habr
[FF D8]
Вам когда-нибудь хотелось узнать как устроен jpg-файл? Сейчас разберемся! Прогревайте ваш любимый компилятор и hex-редактор, будем декодировать это:
Специально взял рисунок поменьше. Это знакомый, но сильно пережатый favicon Гугла:
Последующее описание упрощено, и приведенная информация не полная, но зато потом будет легко понять спецификацию.
Даже не зная, как происходит кодирование, мы уже можем кое-что извлечь из файла.
[FF D8] — маркер начала. Он всегда находится в начале всех jpg-файлов.
Следом идут байты [FF FE]. Это маркер, означающий начало секции с комментарием. Следующие 2 байта [00 04] — длина секции (включая эти 2 байта). Значит в следующих двух [3A 29] — сам комментарий. Это коды символов «:» и «)», т.е. обычного смайлика. Вы можете увидеть его в первой строке правой части hex-редактора.
Немного теории
Очень кратко:
- Обычно изображение преобразуется из цветового пространства RGB в YCbCr.
- Часто каналы Cb и Cr прореживают, то есть блоку пикселей присваивается усредненное значение. Например, после прореживания в 2 раза по вертикали и горизонтали, пиксели будут иметь такое соответствие:
- Затем значения каналов разбиваются на блоки 8×8 (все видели эти квадратики на слишком сжатом изображении).
- Каждый блок подвергается дискретно-косинусному преобразованию (ДКП), являющемся разновидностью дискретного преобразования Фурье. Получим матрицу коэффициетов 8×8. Причем левый верхний коэффициент называется DC-коффициентом (он самый важный и является усредненным значением всех значений), а оставшиеся 63 — AC-коэффициентами.
- Получившиеся коэффициенты квантуются, т.е. каждый умножается на коэффициент матрицы квантования (каждый кодировщик обычно использует свою матрицу квантования).
- Затем они кодируются кодами Хаффмана.
Закодированные данные располагаются поочередно, небольшими частями:
Каждый блок Yij, Cbij, Crij — это матрица коэффициентов ДКП (так же 8×8), закодированная кодами Хаффмана. В файле они располагаются в таком порядке: Y00Y10Y01Y11Cb00Cr00Y20…
Чтение файла
Файл поделен на секторы, предваряемые маркерами. Маркеры имеют длину 2 байта, причем первый байт [FF]. Почти все секторы хранят свою длину в следующих 2 байта после маркера. Для удобства подсветим маркеры:
Маркер [FF DB]: DQT — таблица квантования
- [00 43] Длина: 0x43 = 67 байт
- [0_] Длина значений в таблице: 0 (0 — 1 байт, 1 — 2 байта)
- [_0] Идентификатор таблицы: 0
Оставшимися 64-мя байтами нужно заполнить таблицу 8×8.
[A0 6E 64 A0 F0 FF FF FF]
[78 78 8C BE FF FF FF FF]
[8C 82 A0 F0 FF FF FF FF]
[8C AA DC FF FF FF FF FF]
[B4 DC FF FF FF FF FF FF]
[F0 FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]Приглядитесь, в каком порядке заполнены значения таблицы. Этот порядок называется zigzag order:
Маркер [FF C0]: SOF0 — Baseline DCT
Этот маркер называется SOF0, и означает, что изображение закодировано базовым методом. Он очень распространен. Но в интернете не менее популярен знакомый вам progressive-метод, когда сначала загружается изображение с низким разрешением, а потом и нормальная картинка. Это позволяет понять что там изображено, не дожидаясь полной загрузки. Спецификация определяет еще несколько, как мне кажется, не очень распространенных методов.
- [00 11] Длина: 17 байт.
- [08] Precision: 8 бит. В базовом методе всегда 8. Это разрядность значений каналов.
- [00 10] Высота рисунка: 0x10 = 16
- [00 10] Ширина рисунка: 0x10 = 16
- [03] Количество каналов: 3. Чаще всего это Y, Cb, Cr или R, G, B
1-й канал:
- [01] Идентификатор: 1
- [2_] Горизонтальное прореживание (h2): 2
- [_2] Вертикальное прореживание (V1): 2
- [00] Идентификатор таблицы квантования: 0
2-й канал:
- [02] Идентификатор: 2
- [1_] Горизонтальное прореживание (h3): 1
- [_1] Вертикальное прореживание (V2): 1
- [01] Идентификатор таблицы квантования: 1
3-й канал:
- [03] Идентификатор: 3
- [1_] Горизонтальное прореживание (h4): 1
- [_1] Вертикальное прореживание (V3): 1
- [01] Идентификатор таблицы квантования: 1
Находим H
Маркер [FF C4]: DHT (таблица Хаффмана)
Эта секция хранит коды и значения, полученные кодированием Хаффмана.
- [00 15] Длина: 21 байт
- [0_] Класс: 0 (0 — таблица DC коэффициентов, 1 — таблица AC коэффициентов).
- [_0] Идентификатор таблицы: 0
Следующие 16 значений:
Длина кода Хаффмана: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Количество кодов: [01 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00]Количество кодов означает количество кодов такой длины. Обратите внимание, что секция хранит только длины кодов, а не сами коды. Мы должны найти коды сами. Итак, у нас есть один код длины 1 и один — длины 2. Итого 2 кода, больше кодов в этой таблице нет.
- [03] — значение 1-го кода
- [02] — значение 2-го кода
Далее в файле можно видеть еще 3 маркера [FF C4], я пропущу разбор соответствующих секций, он аналогичен вышеприведенному.
Построение дерева кодов Хаффмана
Мы должны построить бинарное дерево по таблице, которую мы получили в секции DHT. А уже по этому дереву мы узнаем каждый код. Значения добавляем в том порядке, в каком указаны в таблице. Алгоритм прост: в каком бы узле мы ни находились, всегда пытаемся добавить значение в левую ветвь. А если она занята, то в правую. А если и там нет места, то возвращаемся на уровень выше, и пробуем оттуда. Остановиться нужно на уровне равном длине кода. Левым ветвям соответствует значение 0, правым — 1.
Деревья для всех таблиц этого примера:
В кружках — значения кодов, под кружками — сами коды (поясню, что мы получили их, пройдя путь от вершины до каждого узла). Именно такими кодами закодировано само содержимое рисунка.
Маркер [FF DA]: SOS (Start of Scan)
Байт [DA] в маркере означает — «ДА! Наконец-то то мы перешли к финальной секции!». Однако секция символично называется SOS.
- [00 0C] Длина: 12 байт.
- [03] Количество каналов. У нас 3, по одному на Y, Cb, Cr.
1-й канал:
- [01] Идентификатор канала: 1 (Y)
- [0_] Идентификатор таблицы Хаффмана для DC коэффициентов: 0
- [_0] Идентификатор таблицы Хаффмана для AC коэффициентов: 0
2-й канал:
- [02] Идентификатор канала: 2 (Cb)
- [1_] Идентификатор таблицы Хаффмана для DC коэффициентов: 1
- [_1] Идентификатор таблицы Хаффмана для AC коэффициентов: 1
3-й канал:
- [03] Идентификатор канала: 3 (Cr)
- [1_] Идентификатор таблицы Хаффмана для DC коэффициентов: 1
- [_1] Идентификатор таблицы Хаффмана для AC коэффициентов: 1
[00], [3F], [00] — Start of spectral or predictor selection, End of spectral selection, Successive approximation bit position. Эти значения используются только для прогрессивного режима, что выходит за рамки статьи.
Отсюда и до конца (маркера [FF D9]) закодированные данные.
Закодированные данные
Последующие значения нужно рассматривать как битовый поток. Первых 33 бит будет достаточно, чтобы построить первую таблицу коэффициентов:
Нахождение DC-коэффициента
1) Читаем последовательность битов (если встретим 2 байта [FF 00], то это не маркер, а просто байт [FF]). После каждого бита сдвигаемся по дереву Хаффмана (с соответствующим идентификатором) по ветви 0 или 1, в зависимости от прочитанного бита. Останавливаемся, если оказались в конечном узле.
2) Берем значение узла. Если оно равно 0, то коэффициент равен 0, записываем в таблицу и переходим к чтению других коэффициентов. В нашем случае — 02. Это значение — длина коэффициента в битах. Т. е. читаем следующие 2 бита, это и будет коэффициент:
3) Если первая цифра значения в двоичном представлении — 1, то оставляем как есть: DC = <значение>. Иначе преобразуем: DC = <значение>-2^<длина значения>+1. Записываем коэффициент в таблицу в начало зигзага — левый верхний угол.
Нахождение AC-коэффициентов
1) Аналогичен п. 1, нахождения DC коэффициента. Продолжаем читать последовательность:
2) Берем значение узла. Если оно равно 0, это означает, что оставшиеся значения матрицы нужно заполнить нулями. Дальше закодирована уже следующая матрица. В нашем случае значение узла: 0x31.
- Первый полубайт: 0x3 — именно столько нулей мы должны добавить в матрицу. Это 3 нулевых коэффициента.
- Второй полубайт: 0x1 — длина коэффициента в битах. Читаем следующий бит.
- Аналогичен п. 3 нахождения DC-коэффициента.
Читать AC-коэффициенты нужно пока не наткнемся на нулевое значение кода, либо пока не заполнится матрица.
В нашем случае мы получим:
и матрицу:
[2 0 3 0 0 0 0 0]
[0 1 2 0 0 0 0 0]
[0 -1 -1 0 0 0 0 0]
[1 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]Вы заметили, что значения заполнены в том же зигзагообразном порядке? Причина использования такого порядка простая — так как чем больше значения v и u, тем меньшей значимостью обладает коэффициент Svu в дискретно-косинусном преобразовании. Поэтому, при высоких степенях сжатия малозначащие коэффициенты обнуляют, тем самым уменьшая размер файла.
Аналогично получаем еще 3 матрицы Y-канала…
[-4 1 1 1 0 0 0 0] [ 5 -1 1 0 0 0 0 0] [-4 2 2 1 0 0 0 0] [ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0] [-1 0 -1 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0] [-1 -1 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Но! Закодированные DC-коэффициенты — это не сами DC-коэффициенты, а их разности между коэффициентами предыдущей таблицы (того же канала)! Нужно поправить матрицы:
- DC для 2-ой: 2 + (-4) = -2
- DC для 3-ой: -2 + 5 = 3
- DC для 4-ой: 3 + (-4) = -1
[-2 1 1 1 0 0 0 0] [ 3 -1 1 0 0 0 0 0] [-1 2 2 1 0 0 0 0] [ 0 0 1 0 0 0 0 0] [-1 -2 -1 0 0 0 0 0] [-1 0 -1 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0] [ 0 -1 0 0 0 0 0 0] [-1 -1 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [-1 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
Теперь порядок. Это правило действует до конца файла.
… и по матрице для Cb и Cr:
[-1 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0] [ 1 1 0 0 0 0 0 0] [1 -1 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [1 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0]
Вычисления
Квантование
Вы помните, что матрица проходит этап квантования? Элементы матрицы нужно почленно перемножить с элементами матрицы квантования. Осталось выбрать нужную. Сначала мы просканировали первый канал. Он использует матрицу квантования 0 (у нас она первая из двух). Итак, после перемножения получаем 4 матрицы Y-канала:
[320 0 300 0 0 0 0 0] [-320 110 100 160 0 0 0 0]
[ 0 120 280 0 0 0 0 0] [ 0 0 140 0 0 0 0 0]
[ 0 -130 -160 0 0 0 0 0] [ 0 -130 0 0 0 0 0 0]
[140 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 480 -110 100 0 0 0 0 0] [-160 220 200 160 0 0 0 0]
[-120 -240 -140 0 0 0 0 0] [-120 0 -140 0 0 0 0 0]
[ 0 -130 0 0 0 0 0 0] [-140 -130 0 0 0 0 0 0]
[-140 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]… и по матрице для Cb и Cr.
[-170 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 180 210 0 0 0 0 0 0] [180 -210 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [240 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0]И еще ко всем DC-коэффициентам нужно прибавить 1024:
- 320 + 1024 = 1344
- -320 + 1024 = 704
- 480 + 1024 = 1504
- -160 + 1024 = 864
- -170 + 1024 = 854
- 0 + 1024 = 1024
Обратное дискретно-косинусное преобразование
Формула не должна доставить сложностей. Svu — наша полученная матрица коэффициентов. u — столбец, v — строка. syx — непосредственно значения каналов.
Приведу результат вычисления только первой матрицы канала Y (значения округлены):
[138 92 27 -17 -17 28 93 139]
[136 82 5 -51 -55 -8 61 111]
[143 80 -9 -77 -89 -41 32 86]
[157 95 6 -62 -76 -33 36 86]
[147 103 37 -12 -21 11 62 100]
[ 87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87 -50 6 56 79 72 48 29]и для Cb Cr:
[ 60 52 38 20 0 -18 -32 -40] [ 19 27 41 60 80 99 113 120]
[ 48 41 29 13 -3 -19 -31 -37] [ 0 6 18 34 51 66 78 85]
[ 25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[ -4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[ -37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[ -67 -63 -55 -44 -33 -22 -14 -10] [ -5 -9 -17 -28 -39 -50 -58 -62]
[ -90 -84 -71 -56 -39 -23 -11 -4] [ 32 26 14 -1 -18 -34 -46 -53]
[-102 -95 -81 -62 -42 -23 -9 -1] [ 58 50 36 18 -2 -20 -34 -42]4 матрицы Y, и по одной Cb и Cr, так как мы прореживали каналы и 4 пикселям Y соответствует по одному Cb и Cr. Поэтому вычислять так: YCbCrToRGB(Yij, Cb[i/2][j/2], Cr[i/2][j/2])
YCbCr в RGB
R = Y + 1.402 * CrG = Y - 0.34414 * Cb - 0.71414 * CrB = Y + 1.772 * Cb
Если значения выйдут за пределы интервала [0, 255], то присвоить граничные значения.
Вот полученные таблицы для каналов R, G, B для левого верхнего квадрата 8×8 нашего примера:
255 248 194 148 169 215 255 255
255 238 172 115 130 178 255 255
255 208 127 59 64 112 208 255
255 223 143 74 77 120 211 255
237 192 133 83 85 118 184 222
177 161 146 132 145 162 201 217
56 73 101 126 144 147 147 141
0 17 76 126 153 146 127 108
231 185 117 72 67 113 171 217
229 175 95 39 28 76 139 189
254 192 100 31 15 63 131 185
255 207 115 46 28 71 134 185
255 241 175 125 112 145 193 230
226 210 187 173 172 189 209 225
149 166 191 216 229 232 225 220
72 110 166 216 238 231 206 186
255 255 249 203 178 224 255 255
255 255 226 170 140 187 224 255
255 255 192 123 91 138 184 238
255 255 208 139 103 146 188 239
255 255 202 152 128 161 194 232
255 244 215 200 188 205 210 227
108 125 148 172 182 184 172 167
31 69 122 172 191 183 153 134Конец
Вообще я не специалист по JPEG, поэтому вряд ли смогу ответить на все вопросы. Просто когда я писал свой декодер, мне часто приходилось сталкиваться с различными непонятными проблемами. И когда изображение выводилось некорректно, я не знал где допустил ошибку. Может неправильно проинтерпретировал биты, а может неправильно использовал ДКП. Очень не хватало пошагового примера, поэтому, надеюсь, эта статья поможет при написании декодера. Думаю, она покрывает описание базового метода, но все-равно нельзя обойтись только ей. Предлагаю вам ссылки, которые помогли мне:
- ru.wikipedia.org/JPEG — для поверхностного ознакомления
- en.wikipedia.org/JPEG — гораздо более толковая статья о процессах кодирования/декодирования
- JPEG Standard (JPEG ISO/IEC 10918-1 ITU-T Recommendation T.81) — не обойтись без 186-страничной спецификации
- impulseadventure.com/photo — Хорошие подробные статьи. По примерам я разобрался как строить деревья Хаффмана и использовать их при чтении соответствующей секции
- JPEGsnoop — На том же сайте есть отличная утилита, которая вытаскивает всю информацию jpeg-файла
[FF D9]
JPEG — это… Что такое JPEG?
JPEG (произносится «джейпег»[1], англ. Joint Photographic Experts Group, по названию организации-разработчика) — один из популярных графических форматов, применяемый для хранения фотоизображений и подобных им изображений. Файлы, содержащие данные JPEG, обычно имеют расширения (суффиксы) .jpeg, .jfif, .jpg, .JPG, или .JPE. Однако из них .jpg является самым популярным на всех платформах. MIME-типом является image/jpeg.
 Фотография заката в формате JPEG с уменьшением степени сжатия слева направо
Фотография заката в формате JPEG с уменьшением степени сжатия слева направоАлгоритм JPEG позволяет сжимать изображение как с потерями, так и без потерь (режим сжатия lossless JPEG). Поддерживаются изображения с линейным размером не более 65535 × 65535 пикселей.
Область применения
Алгоритм JPEG в наибольшей степени пригоден для сжатия фотографий и картин, содержащих реалистичные сцены с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил в цифровой фотографии и для хранения и передачи изображений с использованием сети Интернет.
С другой стороны, JPEG малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий контраст между соседними пикселами приводит к появлению заметных артефактов. Такие изображения целесообразно сохранять в форматах без потерь, таких как TIFF, GIF или PNG.
JPEG (как и другие методы искажающего сжатия) не подходит для сжатия изображений при многоступенчатой обработке, так как искажения в изображения будут вноситься каждый раз при сохранении промежуточных результатов обработки.
JPEG не должен использоваться и в тех случаях, когда недопустимы даже минимальные потери, например, при сжатии астрономических или медицинских изображений. В таких случаях может быть рекомендован предусмотренный стандартом JPEG режим сжатия Lossless JPEG (который, однако, не поддерживается большинством популярных кодеков) или стандарт сжатия JPEG-LS.
Сжатие
При сжатии изображение преобразуется из цветового пространства RGB в YCbCr (YUV). Следует отметить, что стандарт JPEG (ISO/IEC 10918-1) никак не регламентирует выбор именно YCbCr, допуская и другие виды преобразования (например, с числом компонентов[2], отличным от трёх), и сжатие без преобразования (непосредственно в RGB), однако спецификация JFIF (JPEG File Interchange Format, предложенная в 1991 году специалистами компании C-Cube Microsystems, и ставшая в настоящее время стандартом де-факто) предполагает использование преобразования RGB->YCbCr.
После преобразования RGB->YCbCr для каналов изображения Cb и Cr, отвечающих за цвет, может выполняться «прореживание» (subsampling[3]), которое заключается в том, что каждому блоку из 4 пикселов (2х2) яркостного канала Y ставятся в соответствие усреднённые значения Cb и Cr (схема прореживания «4:2:0»[4]). При этом для каждого блока 2х2 вместо 12 значений (4 Y, 4 Cb и 4 Cr) используется всего 6 (4 Y и по одному усреднённому Cb и Cr). Если к качеству восстановленного после сжатия изображения предъявляются повышенные требования, прореживание может выполняться лишь в каком-то одном направлении — по вертикали (схема «4:4:0») или по горизонтали («4:2:2»), или не выполняться вовсе («4:4:4»).
Стандарт допускает также прореживание с усреднением Cb и Cr не для блока 2х2, а для четырёх расположенных последовательно (по вертикали или по горизонтали) пикселов, то есть для блоков 1х4, 4х1 (схема «4:1:1»), а также 2х4 и 4х2 (схема «4:1:0»). Допускается также использование различных типов прореживания для Cb и Cr, но на практике такие схемы применяются исключительно редко.
Далее яркостный компонент Y и отвечающие за цвет компоненты Cb и Cr разбиваются на блоки 8х8 пикселов. Каждый такой блок подвергается дискретному косинусному преобразованию (ДКП). Полученные коэффициенты ДКП квантуются (для Y, Cb и Cr в общем случае используются разные матрицы квантования) и пакуются с использованием кодирования серий и кодов Хаффмана. Стандарт JPEG допускает также использование значительно более эффективного арифметического кодирования, однако из-за патентных ограничений (патент на описанный в стандарте JPEG арифметический QM-кодер принадлежит IBM) на практике оно используется редко. В популярную библиотеку libjpeg последних версий включена поддержка арифметического кодирования, но с просмотром сжатых с использованием этого метода изображений могут возникнуть проблемы, поскольку многие программы просмотра не поддерживают их декодирование.
Матрицы, используемые для квантования коэффициентов ДКП, хранятся в заголовочной части JPEG-файла. Обычно они строятся так, что высокочастотные коэффициенты подвергаются более сильному квантованию, чем низкочастотные. Это приводит к огрублению мелких деталей на изображении. Чем выше степень сжатия, тем более сильному квантованию подвергаются все коэффициенты.
При сохранении изображения в JPEG-файле указывается параметр качества, задаваемый в некоторых условных единицах, например, от 1 до 100 или от 1 до 10. Большее число обычно соответствует лучшему качеству (и большему размеру сжатого файла). Однако даже при использовании наивысшего качества (соответствующего матрице квантования, состоящей из одних только единиц) восстановленное изображение не будет в точности совпадать с исходным, что связано как с конечной точностью выполнения ДКП, так и с необходимостью округления значений Y, Cb, Cr и коэффициентов ДКП до ближайшего целого. Режим сжатия Lossless JPEG, не использующий ДКП, обеспечивает точное совпадение восстановленного и исходного изображений, однако его малая эффективность (коэффициент сжатия редко превышает 2) и отсутствие поддержки со стороны разработчиков программного обеспечения не способствовали популярности Lossless JPEG.
Разновидности схем сжатия JPEG
Стандарт JPEG предусматривает два основных способа представления кодируемых данных.
Наиболее распространённым, поддерживаемым большинством доступных кодеков, является последовательное (sequential JPEG) представление данных, предполагающее последовательный обход кодируемого изображения поблочно слева направо, сверху вниз. Над каждым кодируемым блоком изображения осуществляются описанные выше операции, а результаты кодирования помещаются в выходной поток в виде единственного «скана», то есть массива кодированных данных, соответствующего последовательно пройденному («просканированному») изображению. Основной или «базовый» (baseline) режим кодирования допускает только такое представление. Расширенный (extended) режим наряду с последовательным допускает также прогрессивное (progressive JPEG) представление данных.
В случае progressive JPEG сжатые данные записываются в выходной поток в виде набора сканов, каждый из которых описывает изображение полностью с всё большей степенью детализации. Это достигается либо путём записи в каждый скан не полного набора коэффициентов ДКП, а лишь какой-то их части: сначала — низкочастотных, в следующих сканах — высокочастотных (метод «spectral selection» то есть спектральных выборок), либо путём последовательного, от скана к скану, уточнения коэффициентов ДКП (метод «successive approximation», то есть последовательных приближений). Такое прогрессивное представление данных оказывается особенно полезным при передаче сжатых изображений с использованием низкоскоростных каналов связи, поскольку позволяет получить представление обо всём изображении уже после передачи незначительной части JPEG-файла.
Обе описанные схемы (и sequential, и progressive JPEG) базируются на ДКП и принципиально не позволяют получить восстановленное изображение абсолютно идентичным исходному. Однако стандарт допускает также сжатие, не использующее ДКП, а построенное на основе линейного предсказателя (lossless, то есть «без потерь», JPEG), гарантирующее полное, бит-в-бит, совпадение исходного и восстановленного изображений. При этом коэффициент сжатия для фотографических изображений редко достигает 2, но гарантированное отсутствие искажений в некоторых случаях оказывается востребованным. Заметно большие степени сжатия могут быть получены при использовании не имеющего, несмотря на сходство в названиях, непосредственного отношения к стандарту JPEG ISO/IEC 10918-1 (ITU T.81 Recommendation) метода сжатия JPEG-LS, описываемого стандартом ISO/IEC 14495-1 (ITU T.87 Recommendation).
Синтаксис и структура
Файл JPEG содержит последовательность маркеров, каждый из которых начинается с байта 0xFF, свидетельствующего о начале маркера, и байта-идентификатора. Некоторые маркеры состоят только из этой пары байтов, другие же содержат дополнительные данные, состоящие из двухбайтового поля с длиной информационной части маркера (включая длину этого поля, но за вычетом двух байтов начала маркера то есть 0xFF и идентификатора) и собственно данных. Такая структура файла позволяет быстро отыскать маркер с необходимыми данными (например, с длиной строки, числом строк и числом цветовых компонентов сжатого изображения).
| Маркер | Байты | Длина | Назначение | Комментарии |
|---|---|---|---|---|
| SOI | 0xFFD8 | нет | Начало изображения | |
| SOF0 | 0xFFC0 | переменный размер | Начало фрейма (базовый, ДКП) | Показывает что изображение кодировалось в базовом режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения (двухбайтовые поля со смещением соответственно 5 и 7 относительно начала маркера), количество компонентов (байтовое поле со смещением 8 относительно начала маркера), число бит на компонент (байтовое поле со смещением 4 относительно начала маркера), а также соотношение компонентов (например, 4:2:0). |
| SOF1 | 0xFFC1 | переменный размер | Начало фрейма (расширенный, ДКП, код Хаффмана) | Показывает что изображение кодировалось в расширенном (extended) режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения, количество компонентов, число бит на компонент, а также соотношение компонентов (например, 4:2:0). |
| SOF2 | 0xFFC2 | переменный размер | Начало фрейма (прогрессивный, ДКП, код Хаффмана) | Показывает что изображение кодировалось в прогрессивном режиме с использованием ДКП и кода Хаффмана. Маркер содержит число строк и длину строки изображения, количество компонентов, число бит на компонент, а также соотношение компонентов (например, 4:2:0). |
| DHT | 0xFFC4 | переменный размер | Содержит таблицы Хаффмана | Задает одну или более таблиц Хаффмана. |
| DQT | 0xFFDB | переменный размер | Содержит таблицы квантования | Задает одну или более таблиц квантования. |
| DRI | 0xFFDD | 4 байта | Указывает интервал повторений | Задает интервал между маркерами RST n в макроблоках. |
| SOS | 0xFFDA | переменный размер | Начало сканирования | Начало первого или очередного скана изображения с направлением обхода слева направо сверху вниз. Если использовался базовый режим кодирования, используется один скан. При использовании прогрессивных режимов используется несколько сканов. Маркер SOS является разделяющим между информативной (заголовком) и закодированной (собственно сжатыми данными) частями изображения. |
| RSTn | 0xFFDn | нет | Перезапуск | Вставляется в каждом r макроблоке, где r — интервал перезапуска DRI маркера. Не используется при отсутствии DRI маркера. n, младшие 3 бита маркера кода, циклы от 0 до 7. |
| APPn | 0xFFEn | переменный размер | Задаётся приложением | Например, в EXIF JPEG-файла используется маркер APP1 для хранения метаданных, расположеных в структуре, основанной на TIFF. |
| COM | 0xFFFE | переменный размер | Комментарий | Содержит текст комментария. |
| EOI | 0xFFD9 | нет | Конец закодированной части изображения. |
Достоинства и недостатки
К недостаткам сжатия по стандарту JPEG следует отнести появление на восстановленных изображениях при высоких степенях сжатия характерных артефактов: изображение рассыпается на блоки размером 8×8 пикселов (этот эффект особенно заметен на областях изображения с плавными изменениями яркости), в областях с высокой пространственной частотой (например, на контрастных контурах и границах изображения) возникают артефакты в виде шумовых ореолов. Следует отметить, что стандарт JPEG (ISO/IEC 10918-1, Annex K, п. K.8) предусматривает использование специальных фильтров для подавления блоковых артефактов, но на практике подобные фильтры, несмотря на их высокую эффективность, практически не используются. Однако, несмотря на недостатки, JPEG получил очень широкое распространение из-за достаточно высокой (относительно существовавших во время его появления альтернатив) степени сжатия, поддержке сжатия полноцветных изображений и относительно невысокой вычислительной сложности.
Производительность сжатия по стандарту JPEG
Для ускорения процесса сжатия по стандарту JPEG традиционно используется распараллеливание вычислений, в частности — при вычислении ДКП. Исторически одна из первых попыток ускорить процесс сжатия с использованием такого подхода описана в опубликованной в 1993 г. статье Касперовича и Бабкина [6], в которой предлагалась оригинальная аппроксимация ДКП, делающая возможным эффективное распараллеливание вычислений с использованием 32-разрядных регистров общего назначения процессоров Intel 80386. Появившиеся позже более производительные вычислительные схемы использовали SIMD-расширения набора инструкций процессоров архитектуры x86. Значительно лучших результатов позволяют добиться схемы, использующие вычислительные возможности графических ускорителей (технологии NVIDIA CUDA и AMD FireStream) для организации параллельных вычислений не только ДКП, но и других этапов сжатия JPEG (преобразование цветовых пространств, run-level, статистическое кодирование и т.п.), причём для каждого блока 8х8 кодируемого или декодируемого изображения. В статье [7] была впервые[источник?] представлена реализация распараллеливания всех стадий алгоритма JPEG по технологии CUDA, что значительно ускорило производительность сжатия и декодирования по стандарту JPEG.
Интересные факты
В 2010 году ученые из проекта PLANETS поместили инструкции по чтению формата JPEG в специальную капсулу, которую поместили в специальный бункер в швейцарских Альпах. Сделано это было с целью сохранения для потомков информации о популярных в начале XXI века цифровых форматах.[8]
См. также
Примечания
Ссылки
Скрытые архивы в jpg файлах
Я решил написать про то, что один незатейливый способ хищения и передачи информации из различных мест. Способ, честно говоря, очень простой, но чтобы додуматься до него, нужно было покопаться в книжках и мануалах. Но на самом деле способ эффектный. Я работаю в крупной компании. И у многих людей из Департамента Безопасности этот способ удивил, а некоторых насторожил.
Начну с теории:
Нам понадобится узнать структуру двух типов файлов JPEG и RAR.
Общая структура файла JPEG:
- заголовок — FFh D8h;
- маркер приложения;
- маркер расширения;
- графическая информация.
Примечания:
…
3. При данном преобразовании все изображение разбивается на мозаики 8х8, с которыми производится специальное спектральное преобразование.
4. При квантовании используются специальные весовые функции, которые либо понижают, либо поднимают те или иные части спектра. Невоспринимаемые глазом цвета удаляются.
5. Выбранная весовая функция успешно сочетается с методом сжатия.
Смысл, в том, что графическая программа осознает, что в блоке информации содержится определённое число байт(цветовых матриц). Т.е. идёт блок информации, а после него можно вставить всё что угодно.

Теперь рассмотрим структуру файла типа RAR.
==========================================================================
RAR archive file format
==========================================================================
Archive file consists of variable length blocks. The order of these
blocks may vary, but the first block must be a marker block followed by
an archive header block.
Each block begins with the following fields:
HEAD_CRC 2 bytes CRC of total block or block part
HEAD_TYPE 1 byte Block type
HEAD_FLAGS 2 bytes Block flags
HEAD_SIZE 2 bytes Block size
ADD_SIZE 4 bytes Optional field - added block size
Field ADD_SIZE present only if (HEAD_FLAGS & 0x8000) != 0
Total block size is HEAD_SIZE if (HEAD_FLAGS & 0x8000) == 0
and HEAD_SIZE+ADD_SIZE if the field ADD_SIZE is present - when
(HEAD_FLAGS & 0x8000) != 0.
In each block the followings bits in HEAD_FLAGS have the same meaning:
0x4000 - if set, older RAR versions will ignore the block
and remove it when the archive is updated.
if clear, the block is copied to the new archive
file when the archive is updated;
0x8000 - if set, ADD_SIZE field is present and the full block
size is HEAD_SIZE+ADD_SIZE.
Declared block types:
HEAD_TYPE=0x72 marker block
HEAD_TYPE=0x73 archive header
HEAD_TYPE=0x74 file header
HEAD_TYPE=0x75 old style comment header
HEAD_TYPE=0x76 old style authenticity information
HEAD_TYPE=0x77 old style subblock
HEAD_TYPE=0x78 old style recovery record
HEAD_TYPE=0x79 old style authenticity information
HEAD_TYPE=0x7a subblock
Comment block is actually used only within other blocks and doesn't
exist separately.
Archive processing is made in the following manner:
1. Read and check marker block
2. Read archive header
3. Read or skip HEAD_SIZE-sizeof(MAIN_HEAD) bytes
4. If end of archive encountered then terminate archive processing,
else read 7 bytes into fields HEAD_CRC, HEAD_TYPE, HEAD_FLAGS,
HEAD_SIZE.
5. Check HEAD_TYPE.
if HEAD_TYPE==0x74
read file header ( first 7 bytes already read )
read or skip HEAD_SIZE-sizeof(FILE_HEAD) bytes
if (HEAD_FLAGS & 0x100)
read or skip HIGH_PACK_SIZE*0x100000000+PACK_SIZE bytes
else
read or skip PACK_SIZE bytes
else
read corresponding HEAD_TYPE block:
read HEAD_SIZE-7 bytes
if (HEAD_FLAGS & 0x8000)
read ADD_SIZE bytes
6. go to 4.
==========================================================================
Block Formats
==========================================================================
Marker block ( MARK_HEAD )
HEAD_CRC Always 0x6152
2 bytes
HEAD_TYPE Header type: 0x72
1 byte
HEAD_FLAGS Always 0x1a21
2 bytes
HEAD_SIZE Block size = 0x0007
2 bytes
The marker block is actually considered as a fixed byte
sequence: 0x52 0x61 0x72 0x21 0x1a 0x07 0x00
Archive header ( MAIN_HEAD )
HEAD_CRC CRC of fields HEAD_TYPE to RESERVED2
2 bytes
HEAD_TYPE Header type: 0x73
1 byte
HEAD_FLAGS Bit flags:
2 bytes
0x0001 - Volume attribute (archive volume)
0x0002 - Archive comment present
RAR 3.x uses the separate comment block
and does not set this flag.
0x0004 - Archive lock attribute
0x0008 - Solid attribute (solid archive)
0x0010 - New volume naming scheme ('volname.partN.rar')
0x0020 - Authenticity information present
RAR 3.x does not set this flag.
0x0040 - Recovery record present
0x0080 - Block headers are encrypted
0x0100 - First volume (set only by RAR 3.0 and later)
other bits in HEAD_FLAGS are reserved for
internal use
HEAD_SIZE Archive header total size including archive comments
2 bytes
RESERVED1 Reserved
2 bytes
RESERVED2 Reserved
4 bytes
File header (File in archive)
HEAD_CRC CRC of fields from HEAD_TYPE to FILEATTR
2 bytes and file name
HEAD_TYPE Header type: 0x74
1 byte
HEAD_FLAGS Bit flags:
2 bytes
0x01 - file continued from previous volume
0x02 - file continued in next volume
0x04 - file encrypted with password
0x08 - file comment present
RAR 3.x uses the separate comment block
and does not set this flag.
0x10 - information from previous files is used (solid flag)
(for RAR 2.0 and later)
bits 7 6 5 (for RAR 2.0 and later)
0 0 0 - dictionary size 64 KB
0 0 1 - dictionary size 128 KB
0 1 0 - dictionary size 256 KB
0 1 1 - dictionary size 512 KB
1 0 0 - dictionary size 1024 KB
1 0 1 - dictionary size 2048 KB
1 1 0 - dictionary size 4096 KB
1 1 1 - file is directory
0x100 - HIGH_PACK_SIZE and HIGH_UNP_SIZE fields
are present. These fields are used to archive
only very large files (larger than 2Gb),
for smaller files these fields are absent.
0x200 - FILE_NAME contains both usual and encoded
Unicode name separated by zero. In this case
NAME_SIZE field is equal to the length
of usual name plus encoded Unicode name plus 1.
0x400 - the header contains additional 8 bytes
after the file name, which are required to
increase encryption security (so called 'salt').
0x800 - Version flag. It is an old file version,
a version number is appended to file name as ';n'.
0x1000 - Extended time field present.
0x8000 - this bit always is set, so the complete
block size is HEAD_SIZE + PACK_SIZE
(and plus HIGH_PACK_SIZE, if bit 0x100 is set)
HEAD_SIZE File header full size including file name and comments
2 bytes
PACK_SIZE Compressed file size
4 bytes
UNP_SIZE Uncompressed file size
4 bytes
HOST_OS Operating system used for archiving
1 byte 0 - MS DOS
1 - OS/2
2 - Win32
3 - Unix
4 - Mac OS
5 - BeOS
FILE_CRC File CRC
4 bytes
FTIME Date and time in standard MS DOS format
4 bytes
UNP_VER RAR version needed to extract file
1 byte
Version number is encoded as
10 * Major version + minor version.
METHOD Packing method
1 byte
0x30 - storing
0x31 - fastest compression
0x32 - fast compression
0x33 - normal compression
0x34 - good compression
0x35 - best compression
NAME_SIZE File name size
2 bytes
ATTR File attributes
4 bytes
HIGH_PACK_SIZE High 4 bytes of 64 bit value of compressed file size.
4 bytes Optional value, presents only if bit 0x100 in HEAD_FLAGS
is set.
HIGH_UNP_SIZE High 4 bytes of 64 bit value of uncompressed file size.
4 bytes Optional value, presents only if bit 0x100 in HEAD_FLAGS
is set.
FILE_NAME File name - string of NAME_SIZE bytes size
SALT present if (HEAD_FLAGS & 0x400) != 0
8 bytes
EXT_TIME present if (HEAD_FLAGS & 0x1000) != 0
variable size
Заметим, что файл этого типа состоит из блоков. Каждый блок начинается с заголовка, а самый первый блок со специального маркера. Тогда получается, что можно до этого маркера вставить любой текст. Всё равно чтение начнётся только с места маркера. Графически можно это представить так.

Таким образом получается, что после JPEG мы можем вставить информацию и перед RAR мы сможем вставить информацию. При этом это никак не повлияет на работу и структуру обеих файлов.
Рассмотрим это на простом примере. Для этого я использовал HEX редактор WinHEX. Графический файл JPEG и RAR архив, включающий в себя различные файлы




Наша цель получить файл следующей структуры

Итак, открываем в WinHex файл JPEG

Теперь идём в конец файла. Вставляем мусор или нулевые байты.А потом вставляем rar файл.
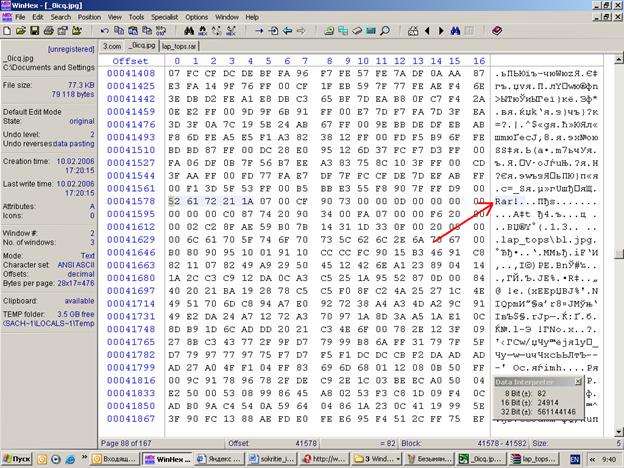
Теперь сохраняем всё в файл JPEG.
Что мы получили.

Размер файла естественно получился суммарным из размеров исходных файлов. Но я бы не сказал, что получился подозрительно большой размер для файла JPEG.
Итак теперь переходим к самому интересному. Проверим теорию на практике.
Сначала открываем файл обычным открытием. Открывается картинка. Теперь меняем расширение на rar. Открываем … и открывается rar архив. Причём в этот архив можно добавлять информацию. Ставить пароль и т.д. А картинку можно без проблем передавать по почте, вставлять на web страницу. Потом скачивать и читать информацию.
Может это всё и очень просто. Но, на мой взгляд, достаточно интересно.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе.
Сачков Илья. (Sachkov, Iliya K. )
jpg Википедия
JPEG (произносится «джейпег»[1], англ. Joint Photographic Experts Group, по названию организации-разработчика) — один из популярных растровых графических форматов, применяемый для хранения фотографий и подобных им изображений. Файлы, содержащие данные JPEG, обычно имеют расширения (суффиксы) .jpg, .jfif, .jpe или .jpeg. Однако .jpg является самым популярным из них на всех платформах. MIME-тип — image/jpeg.
 Фотография заката в формате JPEG с уменьшением степени сжатия слева направо
Фотография заката в формате JPEG с уменьшением степени сжатия слева направоАлгоритм JPEG позволяет сжимать изображение как с потерями, так и без потерь (режим сжатия lossless JPEG). Поддерживаются изображения с линейным размером не более 65535 × 65535 пикселов.
В 2010 году с целью сохранения для потомков информации о популярных в начале XXI века цифровых форматах учёные из проекта PLANETS заложили инструкции по чтению формата JPEG в специальную капсулу, которую поместили в специальное хранилище в швейцарских Альпах[2][3].
Область применения[ | ]
Алгоритм JPEG наиболее эффективен для сжатия фотографий и картин, содержащих реалистичные сцены с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил в цифровой фотографии и для хранения и передачи изображений с использованием Интернета.
Формат JPEG в режиме сжатия с потерями малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий контраст между соседними пикселами приводит к появлению заметных артефактов. Такие изображения целесообразно сохранять в форматах без потерь, таких как JPEG-LS, TIFF, GIF, PNG, либо использовать режим сжатия Lossless JPEG.
JPEG (как и другие форматы сжатия с потерями) не подходит для сжатия изображений при многоэтапной обработке, так как искажения в изображения будут вноситься каждый раз при сохранении промежуточных результатов обработки.
JPEG не должен использоваться и в тех случаях, когда недопустимы даже минимальные потери, например при сжатии астрономических или медицинских изображений. В таких случаях может быть рекомендован предусмотренный стандартом JPEG режим сжатия Lossless JPEG (который, однако, не поддерживается большинством популярных еков) или стандарт сжатия JPEG-LS.
Сжатие[ | ]
При сжатии изображение преобразуется из цветового пространства RGB в YCbCr. Следует отметить, что стандарт JPEG (ISO/IEC 10918-1) никак не регламентирует выбор именно YCbCr, допуская и другие виды преобразования (например, с числом компонентов[4], отличным от трёх), и сжатие без преобразования (непосредственно в RGB), однако спецификация JFIF (JPEG File Interchange Format, предложенная в 1991 году специалистами компании C-Cube Microsystems, и ставшая в настоящее время стандартом де-факто) предполагает использование преобразования RGB->YCbCr.
После преобразования RGB->YCbCr для каналов изображения Cb и Cr, отвечающих за
JPEG 2000, JPEG-XR и WebP в стране упущенных возможностей / .io corporate blog / Habr
Ни для кого не секрет, что первым пунктом в оптимизации сайтов стоит графика. Потому многие крупные корпорации годами пыхтят над разработкой оптимальных форматов, в перспективе способных заменить существующие и разом осчастливить и разработчиков, и пользователей. Но лягушка все никак не превратится в царевну, и в распределении форматов по сети из года в год ничего интересного не происходит:Попробуем разобраться, почему JPEG 2000, JPEG-XR и WebP все еще пасут задних, и действительно ли они такие классные, как заявлено.
JPEG 2000
Отличный формат сжатия, поддерживает компрессию как с потерями качества, так и без, а также прозрачность и прогрессивное сжатие. Заявлено сжатие на 20% лучше, чем в обычном JPEG, и при этом главной фишкой является отсутствие артефактов при сильной компрессии.
Недостаток – слабая поддержка, и от этого очень скудное распространение в сети.
JPEG-XR
Жмет фотки еще лучше и еще быстрее, чем JPEG 2000, возможен вариант lossless, при этом поддерживает разные степени прозрачности и прогрессивное сжатие. Сжимает якобы на 50…75% лучше, чем JPEG, при этом сохраняя приличное качество. Так заявлено. В конце материала поэкспериментируем и проверим, не разводят ли нас.
Поддержка — только старым добрым IE 9 и старше.
WebP
Является полностью открытым стандартом. Поддерживает как lossy, так и lossless, и компрессит картинки на 30…40% лучше JPEG’а. Единственный минус по сравнению с двумя предыдущими – не поддерживает прогрессивное сжатие. Зато гораздо лучше поддерживается браузерами и имеет более светлое будущее.
Поддержка
Не смотря на очевидные преимущества, ни JPEG 2000, ни JPEG-XR, ни WebP пока не светит занять место среди самых популярных форматов сети. Почему? Потому что договориться не могут. Посмотрим на поддержку:
Использование
Неправильно:
<img src="myimage.webp"/>
Так картинка правильно отобразится только в дружественном браузере.
Правильно:
<picture>
<source srcset='myimage.jxr' type='image/vnd.ms-photo'>
<source srcset='myimage.jp2' type='image/jp2'>
<source srcset='myimage.webp' type='image/webp'>
<img srcset='myimage-quant.png' alt='myimage'> </picture>
Встроенную поддержку <picture> имеют только Chrome, Opera и последняя версия Firefox, но с помощью picturefill подстраиваемся и под другие браузеры. После загрузки скрипта добавьте к <head> следующее:
<script async=true src=/path/to/js/picturefill.js></script>
Сработает для WEBP and SVG. Для остальных форматов сразу после тега <script> добавляем:
<script async=true src=/path/to/picturefill.js></script>
<script async=true src=/path/to/jxr.js></script>
<script async=true src=/path/to/jp2.js></script>
Ура. Картинка корректно отобразится в разных браузерах.
Сравниваем JPEG-XR и Webp
Мы решили на конкретном примере проверить, кто же лучше жмет картинки — JPEG-XR или WebP. Для этого мы собрали JPEG-картинки из лучших публикаций Хабры за последний месяц, и каждую поочередно сжали в WebP и в JPEG-XR с помощью этого и этого инструментов.
Средний показатель сжатия для JPEG-XR составил 48%, а для WebP — 60%. Если рассматривать каждую картинку отдельно, то в 80% случаев WebP справился с задачей лучше, чем JPEG-XR на 10…25%.
Вот, например, один и тот же манул, сжатый в JPEG-XR и в WebP.
Как видим, данные отличаются от заявленных.
Конспект
- JPEG 2000, JPEG-XR и WebP — инновационные форматы, не получившие должного признания в вебе.
- Ни один из браузеров не поддерживает хотя бы два из этих форматов.
- К общему знаменателю можно прийти с помощью picturefill.
- Вопреки заявленным значениям, WebP сжимает фотки в среднем на 10…25% лучше, чем JPEG-XR.
Файл:Структура и функции управления качеством в масштабе компании.jpg — Википедия
Материал из Википедии — свободной энциклопедии
Перейти к навигации Перейти к поискуКраткое описание
| ОписаниеСтруктура и функции управления качеством в масштабе компании.jpg | Русский: Структура_и_функции_управления_качеством_в_масштабе_компании показывает функции общего руководства качеством со стороны высших руководителей и оперативного управления качеством руководителями среднего и низового звена управления. |
| Дата | 12 11 2012; 16 11 2012 |
| Источник | Template:Моя книга Управление качеством 2-е изд ИНЖЕКОН, СПб, 1999 |
| Автор | Vitaly yurjevich |
 | Эту диаграмму хорошо бы воссоздать или аккуратно преобразовать в векторный формат SVG. Это даёт несколько преимуществ, подробнее о которых вы можете прочитать на странице Commons:Media for cleanup. Если вам уже сейчас доступна векторная версия данного изображения, загрузите её, пожалуйста. После загрузки замените этот шаблон на следующий: {{Vector version available|Имя загруженного файла.svg}}. |
 | Это изображение (или все изображения в этой статье или категории) были загружены в формате JPEG. Однако, оно содержит информацию, которая могла бы храниться более рационально в формате PNG или SVG. Если у вас имеется такая возможность, пожалуйста, загрузите PNG- или SVG-версию этого изображения без артефактов сжатия, получив его из исходного материала не в формате JPEG, либо убрав существующие артефакты. После того, как это будет сделано, пожалуйста:
|  |
Лицензирование
Я, владелец авторских прав на это произведение, добровольно публикую его на условиях следующей лицензии:

| Этот файл доступен по лицензии Creative Commons Attribution-Share Alike 3.0 Unported | |
https://creativecommons.org/licenses/by-sa/3.0 CC BY-SA 3.0 Creative Commons Attribution-Share Alike 3.0 truetrue |


История файла
Нажмите на дату/время, чтобы посмотреть файл, который был загружен в тот момент.
| Дата/время | Миниатюра | Размеры | Участник | Примечание | |
|---|---|---|---|---|---|
| текущий | 03:28, 1 ноября 2014 | 1261 × 904 (387 Кб) | Brattarb | Структура_и_функции_управления_качеством_в_масштабе_компании.jpg | |
| 20:00, 16 ноября 2012 | 1261 × 1597 (516 Кб) | Vitaly yurjevich | Структура и функции управления качеством Файл показывет структуру и функции общего и оперативного управления качеством в компании [[Ли… | ||
| 10:41, 12 ноября 2012 | 1680 × 1941 (553 Кб) | Vitaly yurjevich | {{Information |Description ={{ru|1=Структура_и_функции_управления_качеством_в_масштабе_компании показывает функции общего руководства качеством со ст… |
Использование файла
Следующая 1 страница использует данный файл:
- Управление качеством
Файл содержит дополнительные данные, обычно добавляемые цифровыми камерами или сканерами. Если файл после создания редактировался, то некоторые параметры могут не соответствовать текущему изображению.
Файл:Структура и анализ Хайку.jpg — Википедия
Материал из Википедии — свободной энциклопедии
Перейти к навигации Перейти к поиску| ОписаниеСтруктура и анализ Хайку.jpg | English: Analysis of haiku. Русский: анализ хайку по системе 5-7-5 | |||||
| Дата | 02 марта 2008 г. | |||||
| Источник | Transferred from ru.wikipedia | |||||
| Автор | Саша Карпенко. Original uploader was Sasha1648 at ru.wikipedia | |||||
| Права (Повторное использование этого файла) | CC-BY-SA-3.0,2.5,2.0,1.0; Released under the GNU Free Documentation License. | |||||
| Другие версии |
|
Лицензирование
Я, владелец авторских прав на это произведение, добровольно публикую его на условиях следующих лицензий:
 | Разрешается копировать, распространять и/или изменять этот документ в соответствии с условиями GNU Free Documentation License версии 1.2 или более поздней, опубликованной Фондом свободного программного обеспечения, без неизменяемых разделов, без текстов, помещаемых на первой и последней обложке. Копия лицензии включена в раздел, озаглавленный GNU Free Documentation License.http://www.gnu.org/copyleft/fdl.htmlGFDLGNU Free Documentation Licensetruetrue |
| Этот файл доступен на условиях лицензий Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic и 1.0 Generic. | |
https://creativecommons.org/licenses/by-sa/3.0 CC BY-SA 3.0 Creative Commons Attribution-Share Alike 3.0 truetrue |
Вы можете выбрать любую из этих лицензий.
Исходный журнал загрузок
Первоначальная страница описания находилась здесь. Все нижеперечисленные имена участников относятся к ru.wikipedia.- 2008-03-06 10:42 Sasha1648 1608×2299× (316075 bytes) {{Изображение | Описание = анализ хайку по системе 5-7-5 | Автор = Саша Карпенко | Время создания = 02 марта 2008 г. | Источник = собственна�
История файла
Нажмите на дату/время, чтобы посмотреть файл, который был загружен в тот момент.
| Дата/время | Миниатюра | Размеры | Участник | Примечание | |
|---|---|---|---|---|---|
| текущий | 16:07, 4 ноября 2009 | 1608 × 2299 (309 Кб) | Rubinbot | {{BotMoveToCommons|ru.wikipedia|year={{subst:CURRENTYEAR}}|month={{subst:CURRENTMONTHNAME}}|day={{subst:CURRENTDAY}}}} {{Information |Description={{ru|анализ хайку по системе 5-7-5}} |Source=Transferred from [http://ru.wikipedia.org |
Использование файла
Следующая 1 страница использует данный файл:
- Участник:Sasha1648